![]()
Hugging Face Transformers を使って日本語 BERT モデルをファインチューニングして感情分析 (with google colab) part02¶
Hugging Face Transformers を使って日本語 BERT モデルをファインチューニングして感情分析 (with google colab) part02
part01 に引き続いて、より大きなデータセットを使い、Trainer class を使いファインチューニングする方法を記載します。
また、学習後の評価方法に関しても記載します。
なお、今回は 5000 件のデータを使って学習を行いますので、GPU の使用を推奨します (著者は google colab を使用して動作確認しています)。
必要なライブラリのインストール¶
!pip install -q transformers fugashi[unidic-lite]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 613.3/613.3 KB 31.3 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 47.4/47.4 MB 19.6 MB/s eta 0:00:00
?25h Preparing metadata (setup.py) ... ?25l?25hdone
Building wheel for unidic-lite (setup.py) ... ?25l?25hdone
import pandas as pd
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
from torch.optim import AdamW
学習データの準備¶
株式会社リクルート 様が公開している Japanese Realistic Textual Entailment Corpus (含意関係データセット) を使用します。
下記、制限があるため注意しましょう。
リクルートは本データセットを非営利的な公共利用のために公開しています。分析・研究・その成果を発表するために必要な範囲を超えて利用すること(営利目的利用)は固く禁じます。
References¶
林部祐太. 知識の整理のための根拠付き自然文間含意関係コーパスの構築. 言語処理学会第26回年次大会論文集,pp.820-823. 2020. (NLP 2020) [PDF] [Poster]
Yuta Hayashibe. Japanese Realistic Textual Entailment Corpus. Proceedings of The 12th Language Resources and Evaluation Conference, pp.6829-6836. 2020. (LREC 2020) [PDF] [bib]
!curl -L -O https://raw.githubusercontent.com/megagonlabs/jrte-corpus/master/data/pn.tsv
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 473k 100 473k 0 0 1275k 0 --:--:-- --:--:-- --:--:-- 1275k
# 各カラムの意味は https://github.com/megagonlabs/jrte-corpus#datapntsv を参照
df = pd.read_csv("pn.tsv", sep='\t', header=None,
names=["id", "label", "text", "judges", "usage"])
# ラベルを 1, 0, -1 --> 0, 1, 2 へ変換
# Label: 2 (Positive), 1 (Neutral), 0 (Negative)
df["label"] = df["label"] + 1
データの確認¶
df.head()
| id | label | text | judges | usage | |
|---|---|---|---|---|---|
| 0 | pn17q00001 | 1 | 出張でお世話になりました。 | {"0": 3} | test |
| 1 | pn17q00002 | 1 | 朝食は普通でした。 | {"0": 3} | test |
| 2 | pn17q00003 | 2 | また是非行きたいです。 | {"1": 3} | test |
| 3 | pn17q00004 | 2 | また利用したいと思えるホテルでした。 | {"1": 3} | test |
| 4 | pn17q00005 | 2 | 駅から近くて便利でした。 | {"0": 1, "1": 2} | test |
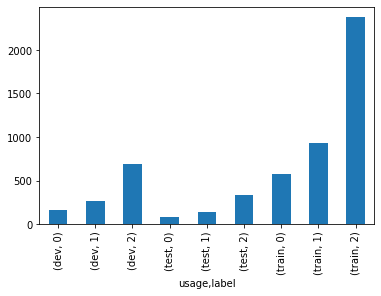
ラベルごとのデータ件数の確認¶
全体的に、positive なラベルが多いようです。
したがって、学習の結果 positive に極端に判定されやすいモデルとなってしまう可能性があるため注意が必要です。
評価指標に accuracy ではなく、F1 score などの不均衡データに関しても正しく評価できるものを選択する必要があります。
df.groupby(["usage", "label"]).size().plot(kind='bar')
<Axes: xlabel='usage,label'>
カスタムデータセットに変換¶
後述する huggingface transformers の Trainer クラスで学習を行うために、カスタムデータセットとして準備します。
usage が train と dev のサンプルを学習用、test のサンプルをテスト用として分割します。
df_train = df[(df["usage"] == "train") | (df["usage"] == "dev")]
train_docs = df_train["text"].tolist()
train_labels = df_train["label"].tolist()
len(train_docs)
5000
df_test = df[df["usage"] == "test"]
test_docs = df_test["text"].tolist()
test_labels = df_test["label"].tolist()
len(test_docs)
553
学習¶
# GPU が利用できる場合は GPU を利用する
device = "cuda:0" if torch.cuda.is_available() else "cpu"
device
'cuda:0'
model_name = "cl-tohoku/bert-large-japanese"
# model_name = "cl-tohoku/bert-base-japanese-v2"
id2label = {0: "NEGATIVE", 1: "NEUTRAL", 2: "POSITIVE"}
label2id = {"NEGATIVE": 0, "NEUTRAL": 1, "POSITIVE": 2}
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3, id2label=id2label, label2id=label2id)
model = model.to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name)
Some weights of the model checkpoint at cl-tohoku/bert-large-japanese were not used when initializing BertForSequenceClassification: ['cls.predictions.transform.dense.bias', 'cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.decoder.weight', 'cls.predictions.decoder.bias', 'cls.seq_relationship.weight', 'cls.predictions.transform.LayerNorm.weight']
- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at cl-tohoku/bert-large-japanese and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
train_encodings = tokenizer(train_docs, return_tensors='pt', padding=True, truncation=True, max_length=128).to(device)
test_encodings = tokenizer(test_docs, return_tensors='pt', padding=True, truncation=True, max_length=128).to(device)
import torch
class JpSentiDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
train_dataset = JpSentiDataset(train_encodings, train_labels)
test_dataset = JpSentiDataset(test_encodings, test_labels)
# We can set `requires_grad` to `False` for all the base model parameters in order to fine-tune only the task-specific parameters.
# Ref: https://huggingface.co/transformers/training.html#freezing-the-encoder
# freeze させないほうが F1 スコアが高くなったためコメントアウトしています
# for param in model.base_model.parameters():
# param.requires_grad = False
# For more detail, see https://korenv20.medium.com/do-we-need-to-freeze-embeddings-when-fine-tuning-our-lm-c8bccf4ffeba
# To calculate additional metrics in addition to the loss, you can also define your own compute_metrics function and pass it to the trainer.
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='weighted', zero_division=0)
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}
1 epoch で試したときは、学習に GPU を使い 7 分程度かかりました。
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=1, # total number of training epochs
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
save_total_limit=1, # limit the total amount of checkpoints. Deletes the older checkpoints.
dataloader_pin_memory=False, # Whether you want to pin memory in data loaders or not. Will default to True
# evaluation_strategy="epoch", # Evaluation is done at the end of each epoch.
evaluation_strategy="steps",
logging_steps=50,
logging_dir='./logs'
)
trainer = Trainer(
model=model, # the instantiated 🤗 Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=test_dataset, # evaluation dataset
compute_metrics=compute_metrics # The function that will be used to compute metrics at evaluation
)
trainer.train()
/usr/local/lib/python3.9/dist-packages/transformers/optimization.py:391: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(
<ipython-input-18-2c7c170fbfaf>:9: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
| Step | Training Loss | Validation Loss | Accuracy | F1 | Precision | Recall |
|---|---|---|---|---|---|---|
| 50 | 0.932100 | 0.803378 | 0.632911 | 0.517217 | 0.602749 | 0.632911 |
| 100 | 0.700200 | 0.523995 | 0.810127 | 0.797865 | 0.807561 | 0.810127 |
| 150 | 0.514500 | 0.478881 | 0.824593 | 0.811550 | 0.823983 | 0.824593 |
| 200 | 0.430900 | 0.469789 | 0.822785 | 0.822782 | 0.840203 | 0.822785 |
| 250 | 0.410400 | 0.584182 | 0.819168 | 0.822111 | 0.842770 | 0.819168 |
| 300 | 0.384600 | 0.369002 | 0.871609 | 0.867412 | 0.868377 | 0.871609 |
<ipython-input-18-2c7c170fbfaf>:9: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
<ipython-input-18-2c7c170fbfaf>:9: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
<ipython-input-18-2c7c170fbfaf>:9: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
<ipython-input-18-2c7c170fbfaf>:9: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
<ipython-input-18-2c7c170fbfaf>:9: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
<ipython-input-18-2c7c170fbfaf>:9: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
TrainOutput(global_step=313, training_loss=0.5584516647143867, metrics={'train_runtime': 344.4271, 'train_samples_per_second': 14.517, 'train_steps_per_second': 0.909, 'total_flos': 864587682150000.0, 'train_loss': 0.5584516647143867, 'epoch': 1.0})
# evaluation のみ実行
trainer.evaluate(eval_dataset=test_dataset)
<ipython-input-18-2c7c170fbfaf>:9: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
{'eval_loss': 0.46805456280708313,
'eval_accuracy': 0.8372513562386981,
'eval_f1': 0.8242864551884431,
'eval_precision': 0.8416320130411961,
'eval_recall': 0.8372513562386981,
'eval_runtime': 7.7473,
'eval_samples_per_second': 71.379,
'eval_steps_per_second': 1.162,
'epoch': 1.0}
評価¶
上記のテストデータの評価結果を見ると、accuracy が 0.75 F1 score が 0.72 で結構良いのではないでしょうか。
さらに epoch 数を増やすことで性能の向上が見込めそうです。
ちなみに、以下のように parameter を freeze させて fine tuning を行った場合は、accuracy が 0.60、F1 値が 0.46 と、かなり低くなってしまいました。
for param in model.base_model.parameters():
param.requires_grad = False
学習の評価指標はデフォルトでは、 runs/**CURRENT_DATETIME_HOSTNAME** に出力されています。
tensorboard での可視化が可能です。
Ref: https://huggingface.co/transformers/main_classes/trainer.html#trainingarguments
%load_ext tensorboard
%tensorboard --logdir logs
fine tune したモデルで推論¶
from transformers import pipeline
sentiment_analyzer = pipeline("sentiment-analysis", model=model.to("cpu"), tokenizer=tokenizer)
sentiment_analyzer("私はこの映画をみることができて、とても嬉しい。")
[{'label': 'POSITIVE', 'score': 0.9754412174224854}]
sentiment_analyzer("猫に足を噛まれて痛い。")
[{'label': 'NEGATIVE', 'score': 0.9508585333824158}]
いい感じに予測できていそうです。
学習済みモデルを保存¶
以下では、colab から google drive に保存する場合の例を示します。
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
save_directory = "/content/drive/MyDrive/Colab Notebooks/trained_models/20210313_bert_sentiment"
tokenizer.save_pretrained(save_directory)
model.save_pretrained(save_directory)
まとめ¶
日本語 BERT large の pre-trained model を fine tuning する方法をご紹介しました。